QEUR23_LLMDSS9: LLM(大規模言語モデル)におけるフィードバック理論の検証
~ 目指せ!ノーベル省! ~
QEU:FOUNDER : “それでは、前回の知見を活かして「Finetuning(FT)の準備」をしましょう。”
QEU:FOUNDER : “もう一度いいますが、現在は「(FTの)準備段階」です。すなわち、学習用のデータセットの生成ですね。”
By the end of this session, attendees will understand:
- How to fine-tune LLMs like Llama-2-7b on a single GPU
- Techniques like parameter efficient tuning and quantization, and how they can help
- How to train a 7b param model on a single T4 GPU (QLoRA)
- How to deploy tuned models like Llama-2 to production
- Continued training with RLHF
- How to use RAG to do question answering with trained LLMs
This session will equip ML engineers to unlock the capabilities of LLMs like Llama-2 on for their own projects.
# ---
このセッションを終えるまでに、参加者は次のことを理解するだろう:
- シングルGPU上でLlama-2-7bのようなLLMを微調整する方法
- パラメータ効率チューニングや量子化などのテクニックと、それらがどのように役立つか
- シングルT4 GPUで7b paramモデルをトレーニングする方法(QLoRA)
- Llama-2のようなチューニングされたモデルを実機に導入する方法
- RLHFによるトレーニングの継続
- 訓練されたLLMで質問応答を行うためにRAGを使用する方法
このセッションは、Llama-2のようなLLMの能力を、MLエンジニアが自身のプロジェクトで発揮できるようにするものです。
D先生 : “・・・すいませんが、以下、ちょっと根本的な質問です。ほんとうに「小さなLLMでユーザーが自からFTすること」って必要なのですかねえ?巨大モデルのGPTは、今現在、ガンガン進化(巨大化)しています。それにRAG技術(LangChainやLlamaIndexなど)を使えば、かなりの問題を解決できるでしょ?”

QEU:FOUNDER : “QEUシステムにおける「Finetuning」の解釈そのものが、従来のもの(↑)とは全く違うんです。ちなみに、いままでに立ち上げた、以下の2件のプロジェクト(↓)は従来的なFinetuneの解釈に基づいているんですがねえ・・・。”
(すでに立ち上げたQEUプロジェクトの2件とは?)
- 世界の中心にある日本語: 常体文と敬体文の情報を学習に使って、日本語のトークンをきめ細かくコントロールする
- 世界平和のためのLLM: 歴史の見方を(立場によって)多面化させる
D先生 : “「世界の中心にある日本語」のプロジェクトはすでに他の組織が作ってしまった(↓)のじゃないですかねえ、残念・・・。我々のソルーション以外のものを使ったのでしょうか。あと、「世界平和のためのLLM」って笑ってしまうほど壮大ですね(笑)。・・・それで?QEUシステムには「もう一つの大テーマ」があるんですか?”


QEU:FOUNDER : “今回、新しく打ち上げるプロジェクトは、さらにすごいですよ!!すぐには理解できないとは思うので、まずは現状のFTというものを理解しましょう。・・・ドン!!”

C部長 : “ん!?なにこれ?フィード・フォワード(FF)って、システム制御理論じゃないですか?ここでいう「MACHINE(機械)」って?”
QEU:FOUNDER : “「MACHINE」はLLM(GPT)のことです。つまり、システム制御理論において「制御システム=人間+機械」にまとめているわけです。いままでのGPTの使い方って、GPTが出した情報を使って、人間が活用してアウトプットを出すという「FFモデル」ですよね。”
D先生 : “・・・ということは、それに対立するあり方として、フィードバック(FB)・システムがあるということですね。”
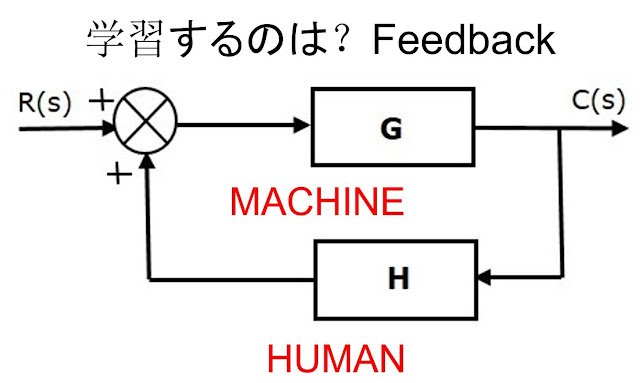

QEU:FOUNDER : “D先生、正解!!システム制御の理論において、概念としては機械と人間の関係をフィードバックにさせることもできます。つまり、LLMを使っているHUMAN(ユーザー)の「ある種の情報」を随時機械に入力しつづけると、この状況が達成できます。”
C部長 : “これはわかるような、わからんような・・・。FBを起こしたい場合には、必然的に自分のLLMに対してFineTuning(FT)することが必要になることはわかります。・・・でも、結局のところ「FEEDBACKによるご利益」というのは?”


QEU:FOUNDER : “小生も、実際のところ、FEEDBACKって何なのかがわからないね。だから、壮大な実験テーマになります。ただし、もしFEEDBACKが可能であれば大変なことが起きるでしょうね。POSITIVE―FEEDBACKが起きるでしょうから・・・。”
D先生 : “「機械に」ポジティブ・フィードバック(PFB)が起きるのでしょうか?「使っている人間(個人)に」PFBが起きるのでしょうか、それとも「社会全体に」(PFBが)起こるのでしょうか・・・。“
QEU:FOUNDER : “いまのところわかっていることは一つだけです。LLMの研究では機械(LLM)を学習させているでしょう?小生が学習させたいのはHUMANに対してなんです。最近のツイッターの情報を見ると、LLMに関する新しい成果が減ってきました。ここにきて開発が一息ついてきたのでしょうか。むしろ、これからは「どのような使い方をするか」にテーマが移ってくるのだと思います。もちろん、ここで「使い方」というのは、つまるところ「HUMANにとって本当に有効な学習データとは何か」ということだが・・・。”
C部長 : “全く訳が分からんが、なにか「面白そうなこと」はわかります。”
D先生 : “やっと、ここからデータセットの話になりましたね。”


QEU:FOUNDER : “それでは、これからデータセットをつくるプログラムに入りましょう。・・・ドン!!”
Q:データフレームの情報を、以下のALPACA形式のJSONファイルに出力するためのPythonプログラムを作成してください。
ALPACA形式```
[
{
"instruction": "Give three tips for staying healthy.",
"input": "",
"output": "1.Eat a balanced diet and make sure to include plenty of fruits and vegetables. \n2. Exercise regularly to keep your body active and strong. \n3. Get enough sleep and maintain a consistent sleep schedule."
},
{
"instruction": "What are the three primary colors?",
"input": "",
"output": "The three primary colors are red, blue, and yellow."
},
]
```
D先生 : “またまた、GPTに呪文を入力してプログラムをもらおうという魂胆・・・(笑)?”
QEU:FOUNDER : “実際には、この呪文で生成するコードでは完全には動かないですが、肝心のALPACA形式を踏まえたプログラムができますよ。それでは、手直ししたプログラムをドン!!”
# from JSONLINE to JSON(ALPACA)
import pandas as pd
import json
# -----
# ファイルを読み込む
df = pd.read_json('cats_stories_train.jsonl', orient='records', lines=True)
print(df)
# -----
# ALPACA形式のJSONファイルに出力する関数を定義する
def df_to_alpaca(df):
# 空のリストを作成
alpaca_list = []
# データフレームの各行に対してループ
for index, row in df.iterrows():
# instruction, input, outputのキーを持つオブジェクトを作成
alpaca_obj = {
"instruction": f"{row['question']}",
"input": "",
"output": f"{row['answer']}"
}
# リストに追加
alpaca_list.append(alpaca_obj)
return alpaca_list
# 関数を呼び出してデータフレームをALPACA形式に出力する
alpaca_list = df_to_alpaca(df)
print(alpaca_list)
# ALPACAリストをJSONファイルに出力する
with open("alpaca_cats_stories_train.json", "w") as f:
json.dump(alpaca_list, f, indent=4)
QEU:FOUNDER : “このJSON-LINEのデータをALPACA形式に変換したいと思います。”

D先生 : “ん!?ちょっと待った!!もしかして、このデータって猫の・・・?”
QEU:FOUNDER : “そうです。「猫の飼い方」をデータセットにしました。だいたいレコードが500件ぐらいあります。それでも、情報を集めるのに結構苦労しました・・・。”
D先生 : “まあ、ふつうに情報収集という作業は大変でしょうね。でも、なんで猫なの?”
QEU:FOUNDER : “どんな使い方をすれば、LLMのシステムがフィードバックになるのかを考えてみました。こんな使い方(↓)をイメージしました。”
(HUMAN-MACHINE対話:ケース1)
- Q(HUMAN): 〇〇ちゃん(猫の名前)が少し元気ないんです。くしゃみをしています。
- A(MACHINE): 同じことは2年前にありました。あのときは医者に行きました。年を取って免疫が落ちちゃったんじゃないですか?獣医に行ってみればいいと思います。”
C部長 : “なるほどね。いままでのLLMとは全くアウトプットが違います。
QEU:FOUNDER : “まずは仮説を設定しました。LLMの中を流通する情報の中に「経験」や「感情(感覚)」が必要なんでしょうね。もちろん、学習する内容には相当の「知識も」中心になるんですが・・・。”
D先生 : “もし、ユーザーがつながるとLLMがもう一歩進歩するでしょうね。”
(HUMAN-MACHINE対話:ケース2)
- Q(HUMAN): 〇〇ちゃん(猫の名前)が少し元気ないんです。一日に2回程度、くしゃみをしています。
- A(MACHINE): それと同じことは2年前にありました。あのときは医者に行きました。あと、FACEBOOKのグループの〇〇さんも同じ経験があり、▽▽というサプリが効くそうです。一週間程度で自然に治り、医者に行かずとも良かったそうです。"
QEU:FOUNDER : “ここまでくると、今度は人間(HUMAN)が学習して、システムがPOSITIVE-FEEDBACKすることになるでしょう。今回の「たたき台データセット(猫)」は、このための第一歩です。D先生・・・、ノーベル省ほぢい・・・。
D先生: “・・・私の直感ですが、世界の誰かが似たようなことをもう始めていると思います。それでも、これほどの大テーマならば、自分たちなりにやってみる価値は十分ありますがね。・・・でも、ノーベル賞でしょ?省じゃない・・・。”
~ まとめ ~
・・・ 前回のつづきです(「愛国者は買え!の巻」) ・・・
D先生 : “相変わらず、この件(↓)で世の中が盛り上がっていますが・・・。”
QEU:FOUNDER : “それが「安い=J国の技術力!」に進化しちゃった(笑)。”

D先生 : “現在は、「第三位があなどれない」という訳なんですね。”
QEU:FOUNDER : “もし、「第三位にも負けちゃった」らどうするのかなあ・・・?”
D先生 : “問題なし。愛国の力は無限である(笑)。”

QEU:FOUNDER : “なるほど!負けそうになったら、国民がもう一台買えばいいわけか!!でも、小生にもそんな金がないのだが・・・。”
D先生 : “奥の手があります(笑)。実際には笑い事じゃないが・・・。”

QEU:FOUNDER : “あ~あ、美しい国・・・。”


コメント
コメントを投稿